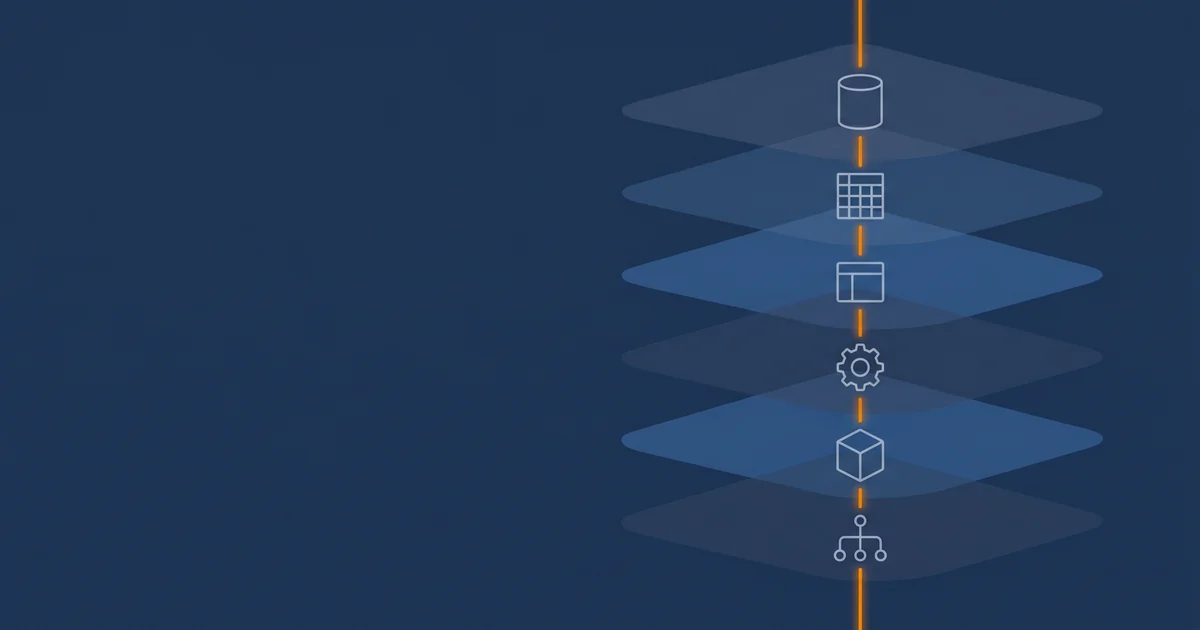
Eine moderne Datenplattform besteht 2026 aus sechs Schichten, die über offene Standards miteinander sprechen. Object Storage als Fundament, Parquet als Format, ein Tabellenformat wie Iceberg oder Delta Lake als Konsistenzschicht, eine Verarbeitungs-Engine wie Spark, Polars oder DuckDB für Transformationen, eine analytische Datenbank wie ClickHouse oder BigQuery für Echtzeit-Antworten, und ein Python-basierter Werkzeugkasten für maschinelles Lernen. Jede Schicht löst eine andere Aufgabe, jede lässt sich austauschen, ohne dass die anderen mitziehen müssen. Genau diese Trennung ist der eigentliche Wert der Architektur.
Wer eine Datenplattform aufbaut, sollte den Stack als Ganzes verstehen, bevor er Werkzeuge auswählt. Dieser Kompaktüberblick liefert die wichtigsten Aussagen aus den fünf Hauptteilen der Serie und ergänzt sie um konkrete Empfehlungen für unterschiedliche Unternehmensgrößen. Wer tiefer einsteigen möchte, findet in den jeweiligen Teilen die ausführlichen Begründungen, Marktdaten und Werkzeugvergleiche.
Die sechs Schichten im Bild
Object Storage ist die unterste Schicht. Daten liegen als unveränderliche Objekte in Buckets, adressierbar über die S3-API. Die wichtigsten Hyperscaler-Optionen sind AWS S3, Azure Blob Storage und Google Cloud Storage, daneben Cloudflare R2 (kein Egress), Backblaze B2 (sehr günstig, kostenloser Egress bis zur dreifachen Storage-Menge) und Hetzner Object Storage (EU-Standort, seit 1. April 2026 bei 6,49 EUR pro Monat im Standardpaket, vorher 4,99 EUR). Auch IONOS bietet ein klares Pay-as-you-go-Modell in deutschen Rechenzentren an. Selbstbetrieb auf SeaweedFS oder Garage ist eine ernsthafte Option für mittlere Setups. RustFS ist ein vielversprechender MinIO-Nachfolger, im April 2026 in der Beta-Phase, mit angekündigter General Availability für Juli 2026. MinIO selbst wurde am 12. Februar 2026 auf GitHub archiviert.
Parquet ist das Standardformat für analytische Tabellen. Spaltenorientiert, mit eingebetteten Schema-Informationen, fünf- bis zehnfach kleiner als CSV bei gleichem Inhalt. CSV-Daten gehören möglichst früh nach der Aufnahme in Parquet konvertiert, idealerweise in einer Bronze-Schicht.
Tabellenformate wie Apache Iceberg (1.10), Delta Lake (4.2 auf Spark 4.1) und Apache Hudi (1.1) heben das nackte Parquet auf eine echte Tabellenabstraktion mit ACID-Transaktionen, Schema-Evolution und Time Travel. Iceberg gewinnt 2026 deutlich an Boden, vor allem nach der Tabular-Akquisition durch Databricks (Juni 2024, etwa zwei Milliarden Dollar) und der nativen Iceberg-Unterstützung in Unity Catalog. Apache Polaris hat sich als vendor-neutraler Katalog mit der Version 1.4.0 vom 21. April 2026 etabliert, jetzt mit Credential Vending für Azure und Google Cloud Storage und Catalog Federation. Snowflake hat am 14. April 2026 zusätzlich Storage für Apache Iceberg in Preview gebracht.
Verarbeitungs-Engines sind die Werkzeuge, mit denen aus den Tabellen tatsächlich Auswertungen werden. Apache Spark (4.1.1 stabil, 4.2 in Preview) bedient verteilte Workloads im Terabyte- bis Petabyte-Bereich. Polars (1.40.1 vom 22. April 2026) läuft auf einer einzigen, gut ausgestatteten Maschine und schlägt Pandas in den meisten Benchmarks deutlich, mit der neuen Streaming-Engine sogar bei Datensätzen, die nicht in den Hauptspeicher passen. DuckDB ist die eingebettete OLAP-Datenbank für Notebooks und Anwendungen, mit DuckDB 1.5.2 vom 13. April 2026 als aktueller Version und dem zeitgleich veröffentlichten produktionsreifen DuckLake-1.0-Format. Die drei schließen einander nicht aus, sondern ergänzen sich.
Analytische Datenbanken liefern Antwortzeiten unter einer Sekunde, etwa für Dashboards oder eingebettete Auswertungen. ClickHouse (aktuell 25.12.10.7) ist der Open-Source-Standard, mit hervorragender Performance, moderaten Hardware-Anforderungen und seit den 25.x-Releases voller Iceberg-Read/Write-Parität. BigQuery (mit Fluid Scaling für 34 Prozent Kostenreduktion), Snowflake (mit Cortex AI) und Databricks SQL (mit Photon-Engine) sind die Hyperscaler-Alternativen. Amazon Redshift Serverless bietet seit Februar 2026 zusätzlich Drei-Jahres-Reservierungen mit bis zu 45 Prozent Rabatt.
Maschinelles Lernen schließlich findet in der Python-Welt statt. Die Nixtla-Bibliotheken (StatsForecast 2.0.3, MLForecast, NeuralForecast 3.1.7) sind die Referenz für Zeitreihenprognose. Pretrainierte Foundation-Modelle wie Chronos (Amazon), TimesFM (Google) oder Moirai (Salesforce) ergänzen das Bild seit Ende 2025 als Zero-Shot-Optionen. Skalierungsstrategien reichen von der einzelnen Maschine über Spark mit Pandas-UDFs bis hin zu Ray (seit September 2025 in der Linux Foundation und im PyTorch-Ecosystem) oder Dask in reinen Python-Stacks. MLflow 3.11.1 vom 5. März 2026 ist Standard für Modell-Tracking, Feast für Feature-Stores.
Wann lohnt sich welche Schicht?
Die wichtigsten Faustregeln für die Schichten lassen sich knapp zusammenfassen.
| Größenordnung | Speicher | Engine | OLAP | ML |
|---|---|---|---|---|
| Klein (unter 1 TB) | Hetzner oder IONOS Object Storage | DuckDB 1.5.2 | DuckDB im Anwendungsprozess | Lokale Modelle, einzelne Maschine |
| Mittel (1 bis 50 TB) | Hetzner oder Hyperscaler | Polars 1.40 plus DuckDB | ClickHouse im Eigenbetrieb | MLForecast auf einer Maschine |
| Groß (50 TB bis 1 PB) | Hyperscaler oder Ceph | Spark 4.x plus Polars | ClickHouse Cloud oder BigQuery | Spark mit Pandas-UDFs oder Ray |
| Sehr groß (über 1 PB) | Hyperscaler mit Iceberg 1.10 | Spark mit Lakehouse | Snowflake oder Databricks SQL | Hyperscaler-ML-Plattform |
Diese Tabelle ist kein dogmatisches Rezept. Sie zeigt nur die Werkzeuge, mit denen die jeweilige Größenordnung erfahrungsgemäß am wirtschaftlichsten bedient wird. Wer von einer Größe in die nächste wächst, kann die Werkzeuge schichtweise austauschen, ohne dass die übrige Architektur kippt. Genau diese Schichtweise ist das, was die offenen Standards seit ungefähr fünf Jahren möglich gemacht haben. Vor 2020 waren solche Wechsel deutlich teurer, weil proprietäre Formate und enge Werkzeug-Kopplungen jede Migration zu einem Großprojekt machten.
Eine zweite Beobachtung gehört dazu. Die Schwelle, ab der eine einzige Maschine nicht mehr ausreicht, ist in den letzten Jahren deutlich gestiegen. Eine moderne Maschine mit hochkernigen AMD-EPYC-Prozessoren und 1 bis 1,5 TB RAM kostet im Eigenbetrieb (etwa über die Hetzner DX-Serie) monatlich im niedrigen vierstelligen Eurobereich, in der Cloud bei den Hyperscalern zwischen 3.000 und 5.000 EUR. Auf so einer Maschine laufen viele Workloads, die früher einen Cluster verlangt hätten. Wer seine Plattform auf eine starke Maschine plant, statt von Anfang an verteilt zu denken, spart oft Komplexität und Kosten gleichzeitig.
Welche Empfehlungen passen zu welcher Unternehmensgröße?
Kleine Datenteams (zwei bis fünf Personen, unter 5 TB) kommen mit einem einzelnen Server, einer Hetzner-Object-Storage-Instanz und DuckDB plus Polars sehr weit. Die ganze Plattform kostet im Eigenbetrieb deutlich unter 1.000 EUR pro Monat und lässt sich in einer Woche einrichten. Iceberg-Tabellen sind machbar, aber selten zwingend nötig. Für Reporting und Analytics reicht häufig DuckDB direkt im Anwendungsprozess. Wer ML-Vorhersagen braucht, fängt mit StatsForecast 2.x oder MLForecast auf einer einzelnen Maschine an.
Mittlere Plattformen (sechs bis zwanzig Personen, 5 bis 100 TB) profitieren von einer klaren Schichtentrennung. Hetzner Object Storage als Lake, Parquet plus Iceberg 1.10, Polaris 1.4 als Katalog, Polars und DuckDB für Transformationen, ClickHouse im Eigenbetrieb für Dashboards. Spark wird hier oft erst nötig, wenn Streaming-Pipelines oder Petabyte-Volumen ins Spiel kommen. Wer Cloud-verankert ist, ersetzt Hetzner durch S3 oder GCS und ClickHouse durch BigQuery oder ClickHouse Cloud. Die monatlichen Kosten liegen typischerweise zwischen 2.000 und 8.000 EUR.
Große Datenplattformen (mehr als zwanzig Personen, über 100 TB) brauchen die volle Schichtarchitektur und ein dediziertes Plattform-Team. Spark für ETL, Polars und DuckDB für ad-hoc Analysen, ClickHouse oder BigQuery für interaktive Auswertungen, MLflow 3 oder Feast für die ML-Schicht, Polaris als zentraler Katalog. Selbstbetrieb wird ab dieser Größe wirtschaftlich, verlangt aber eine bewusste Investition in Wartung und Monitoring. Hyperscaler-Plattformen sind eine ernsthafte Alternative, wenn die organisatorische Bindung keine Hürde ist. Die monatlichen Kosten reichen von 8.000 bis weit über 50.000 EUR, abhängig von Workload und Anbieter.
Drei Prinzipien, die sich durchsetzen
Erstens, S3-Kompatibilität ist nicht verhandelbar. Wer eine proprietäre Speicherschnittstelle wählt, koppelt sich an einen einzelnen Anbieter. Die Geschichte der MinIO-Archivierung am 12. Februar 2026 zeigt eindrücklich, dass auch Open-Source-Projekte verschwinden können. Die offene API garantiert, dass die Migration kein Totalausfall wird.
Zweitens, Trennung der Schichten ist nicht optional. Speicher, Format, Tabelle, Engine, OLAP-Datenbank und ML-Werkzeugkasten sind eigenständige Komponenten. Wer sie in eine monolithische Plattform zwingt, gewinnt kurzfristig Bequemlichkeit und verliert langfristig Flexibilität. Die Werkzeugauswahl pro Schicht ist die einfachere Aufgabe. Die schwierige liegt in der bewussten Disziplin, die Schichten getrennt zu halten.
Drittens, Klein anfangen, dann skalieren. Eine einzelne starke Maschine mit Polars, DuckDB, Hetzner Object Storage und ein paar Parquet-Dateien tragen erstaunlich weit. Spark, ClickHouse und ein vollständiges Lakehouse-Setup sind hervorragende Werkzeuge, aber jedes davon bringt Komplexität mit. Wer zu früh in alle Schichten gleichzeitig investiert, baut sich eine Plattform, die mehr Probleme schafft als löst.
Ein vierter Punkt, den viele Plattform-Architekten unterschätzen, sind die organisatorischen Voraussetzungen. Eine technisch saubere Datenarchitektur scheitert oft nicht an Werkzeugen, sondern an unklaren Verantwortlichkeiten. Wer eine Plattform aufbaut, sollte parallel klären, wer für welches Datenprodukt geradesteht, wie Schemata versioniert werden und wie Datenqualität gemessen wird. Diese Fragen wirken weniger glamourös als die Toolwahl, sind aber häufig der eigentliche Hebel für eine gut funktionierende Plattform.
Fazit
Die wichtigste Botschaft dieser Serie ist nicht die Auswahl einer bestimmten Werkzeugkombination. Sie lautet: Datenarchitektur 2026 lebt von der Trennung der Schichten und dem Vertrauen in offene Standards. Object Storage hält die Rohdaten, Parquet bringt sie in ein effizientes analytisches Format, ein Tabellenformat liefert die Konsistenzgarantien, eine Verarbeitungs-Engine transformiert, eine analytische Datenbank antwortet schnell, und ein eigenständiger Werkzeugkasten kümmert sich um maschinelles Lernen. Was diese Schichten zusammenhält, sind S3, Parquet und SQL als gemeinsame Brücken.
Wer beim Aufbau einer Plattform auf diese Trennung achtet, gewinnt nicht nur Leistung, sondern vor allem die Freiheit, einzelne Komponenten austauschen zu können, ohne das Gesamtsystem in Frage zu stellen. Diese Verhandlungsposition gegenüber Anbietern und Werkzeugen ist 2026 das wertvollste, was eine Datenarchitektur ihrer Organisation geben kann.
Die fünf Hauptteile dieser Serie führen jede der sechs Schichten im Detail aus, mit konkreten Werkzeugvergleichen, DACH-Beispielen, Pricing-Tabellen und Wertungen. Teil 1 startet beim Object Storage und der Frage, welche Anbieter und Open-Source-Projekte 2026 wirklich tragfähig sind.